By Craig Silverstein
Bundling JavaScript files
The traditional advice for web developers is to bundle the JavaScript files used by their webpages into one or (at most) a few “packages.” Multiple tools have been developed to do this, such as Browserify and Webpack. They tend to work like this: for a given HTML page, you write a single JavaScript source file that provides all the JS logic needed for that page. You then use a bundler to create a package that includes that JavaScript source file plus all its dependencies; that package is then served via a single HTTP request.
The opposite of bundling is to just serve all those JavaScript source files separately: your HTML page has a <script> tag for your “main” JS source file, but before that it has <script> tags for each of its dependencies as well.
There is also a middle ground — this is what Khan Academy does — of bundling together JavaScript source files into packages, but into a small number of semantically related packages, rather than a single package per HTML page.
There are reasons in favor of each of these approaches:
| Approach | Pros | Cons |
|---|---|---|
| Package per page |
|
|
| Separate JS files |
|
|
| Hybrid |
|
|
Basically, the package-per-page approach gives up cacheability in favor of minimizing HTTP requests: if you visit a second page on the same website, you’ll have to download a whole new JavaScript package, even though it includes many of the same dependencies as the old page. If it sticks in your craw that your users have to re-download jQuery every time they click on a new page on your site, per-page packages are not for you.
But if you don’t do any packaging at all, while cacheability is excellent, your HTTP performance goes down the tubes; if your page requires dozens of JavaScript source files, you have to download each separately, paying HTTP (plus maybe SSL) overhead each time. Plus, most browsers limit the number of simultaneous fetches they’ll do, meaning these downloads can’t even all happen in parallel. This ends up being very slow.
Khan Academy uses a hybrid approach: we combine JavaScript source files into packages, but we do so based on what files are used together. So we have one package that has JavaScript specific to video pages, and another specific to our CS content, and another specific to internationalization, and so forth. A given HTML page will need several such packages, and often will need only some of the source files in each package. On a given page, you waste time downloading extra bytes for unused JavaScript source files, but hopefully save time due to some packages being cached in the browser.
HTTP/2.0 changes the calculus…or does it?
HTTP/2.0 (and its predecessor SPDY) changes all the considerations here. HTTP/2.0 has advanced flow control techniques like multiplexing. This means that you can use a single connection to download dozens of JavaScript files, and download them all in parallel. Suddenly the “cons” column of the “separate JS files” approach empties out.
As more and more browsers support HTTP/2.0 (over 60% of all browsers worldwide), you’d expect there to be a groundswell of support for leaving JavaScript packaging behind and moving to just serving JavaScript source files directly. And indeed, there is a mini-groundswell, at least.
Khan Academy spent several months rearchitecting its system to move from a package-based scheme to one that just served JavaScript source files directly, at least for clients that support HTTP/2.0. And here’s what we found:
Performance got worse.
On investigation we found out there were two reasons for this:
- We were serving more bytes due to reduced compression quality
- The server had unexplained delays serving dozens of JS files
The sections below explore these issues in more detail.
Our conclusion is it is premature to give up on bundling JavaScript files at this time, even for HTTP/2.0 clients. In particular, bundling into packages will continue to perform better than serving individual JavaScript source files until HTTP/2 has a better story around compression.
Bundling improves compression
All modern servers and browsers compress (most) data being sent over the wire, typically using the zlib DEFLATE algorithm (colloquially, “zlib”). This results in major time savings: for one Khan Academy HTML page, the associated JavaScript content is 2,421,176 bytes uncompressed, but only (!) 646,806 bytes compressed, or about a quarter the size.
When we changed that page to download JavaScript source files individually rather than as packages, the uncompressed size went down to 2,282,839 bytes (a nice 5% savings). This is because we could omit JavaScript files that were not actually needed on this page, but were included in one of the required packages regardless. But the compressed size went up, to 662,754 bytes!
| Size | Packages | Individual files | Pct difference |
|---|---|---|---|
| uncompressed JS | 2,421,176 bytes | 2,282,839 bytes | -5.7% |
| compressed JS | 646,806 bytes | 662,754 bytes | +2.5% |
| number of files | 28 files | 296 files | (+921%) |
On reflection, this is no surprise: due to how zlib operates, using a sliding window of previous text to guide its compression, it does much better on big files than small ones. In particular, it will always compress 100 1K files worse (in aggregate) than the single 100K file you get by concatenating them all together.
(More details: at a high level, zlib compresses like this: it goes through a document, and for every sequence of text it’s looking at, it sees if that text had occurred previously in the document. If so, it replaces that sequence of text by a (space-efficient) pointer to that previous occurrence. It stands to reason that the further along in the document it goes, the more “previous text” there is for finding a potential match and thus an opportunity for compression.
This discussion omits some details, like the limited size of the sliding window, that do not affect the overall conclusion. For more details on zlib, and the LZ77 algorithm it implements, see Wikipedia.)
zlib actually has a mechanism built in for improving compression in the case of many small files: you can specify a “preset dictionary”, which is just a big string of bytes. Basically, when compressing with a preset dictionary, you can replace text either with a pointer to earlier in the document, or into the preset dictionary. With a preset dictionary, early parts of the document have more opportunities to find a good pointer match.
HTTP/2 actually takes advantage of this feature by hard-coding a preset dictionary that servers and browsers must use when talking HTTP/2. Unfortunately for us, that preset dictionary has text related to HTTP headers, and is useless at improving the compression quality of JavaScript files.
Preset dictionaries are hard to use as part of HTTP because both the server and client must agree on the contents of the preset dictionary or the data will get corrupted. HTTP/2 solves this problem by hard-coding a single value in both places. For our application, though, of improving compression of many JavaScript files, there would have to be some way for the server to communicate the preset dictionary to the client.
This takes time, of course, and really only works well if it’s supported at the protocol layer. That said, for cases like this it would be a significant net win overall. But it likely wouldn’t be easy to augment the HTTP/2 spec to allow for something like this in a safe way!
HTTP/2.0 has service issues
In addition to increasing bandwidth, moving away from packages increased latency due to sub-optimal behavior of our webserver when serving hundreds of JavaScript source files. Our analysis of this behavior was not entirely satisfactory, since we do not control our webserver (we use Google App Engine).
However, by analyzing HAR files we could see the effect plainly:

Not all the JavaScript files are requested at the same time, there’s a small gap between requesting each one. About halfway down the image (you can click on it to see this more clearly), there is a large gap. Those files also require over a second to download, though it’s difficult to tell exactly what’s going on due to HTTP/2 multiplexing. But clearly something is not as efficient as it could be.
These tests were done on a recent Chrome browser. It’s possible other browsers would have different effects. And the test was emulating a super-fast FiOS connection; you can see that all the time is taken in the green part of the bars (time to first byte) and not the blue part (time to download the full file).
Furthermore, reloading the page gave HAR files looking substantially different each time. But the end result was the same: a page that had much more latency than when using packages.
When we stuck with a relatively small number of packages, the waterfall was consistent and reliable (and much shorter!):
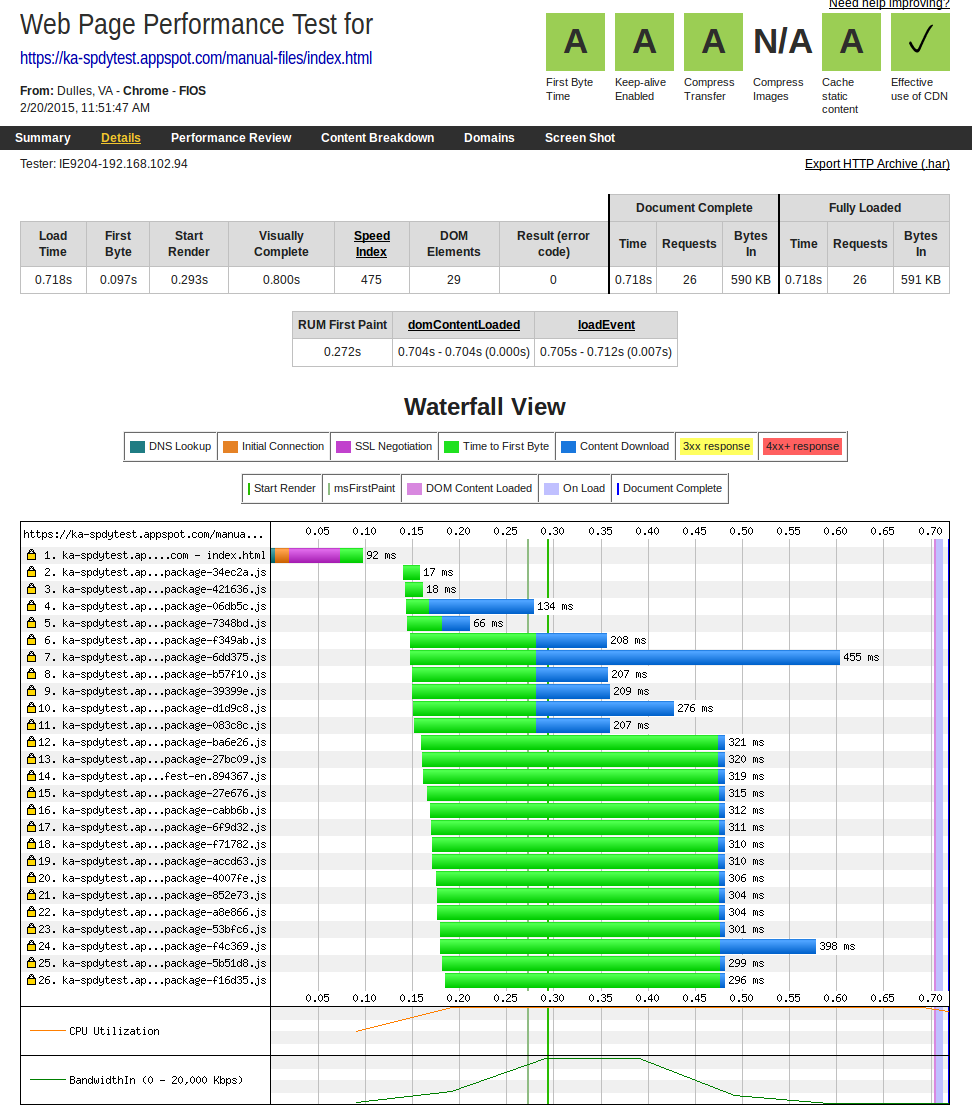
The time-to-first byte is still longer than we would like, for reasons we are not entirely sure of, but it’s much more consistent than in the individual-source-file case!
(If you are curious, entry #7, with the longest blue bar, is for our ‘core’ JavaScript package which includes jQuery, React, and a few other large, rarely-changing libraries. For our test, we disabled the browser cache, but our hope is most of our users will need to download that package only once, getting the contents from their browser cache after that.)
It’s all about the bytes
It may not have escaped your notice that 662,754 bytes is a lot of bytes for JavaScript for a single HTML page, and 296 files is a lot of files. “What are you doing on that page?” you may well be wondering.
We are wondering that too. The page in question is the Khan Academy homepage for logged in users, and its acquired a lot of, um, functionality over the years.
The end result of our analysis is that our page isn’t going to load any faster until we reduce the amount of JavaScript we use on the page. Tricks like trying to load a bunch of stuff in parallel, or aggressive caching, might seem like appealing shortcuts, but nothing replaces just auditing the code and making it need less “stuff.”
Summary
HTTP/2.0, with its multiplexing, header compression, and the like, offers the promise of the best of all worlds when it comes to downloading JavaScript: great local caching, great download efficiency, no wasted bytes, and a simpler serving infrastructure to boot. All you have to do is give up your packaging system and download all your JavaScript source files individually.
The reality is not so rosy. Due to degraded compression performance, the size of the data download with individual source files ends up being higher than with packages, despite having achieved ‘no wasted bytes’. Likewise, the promised download efficiency has yet to show up in the wild, at least for us. It seems that, for the moment at least, JavaScript packaging is here to stay.