
By Colin Fuller
At Khan Academy, we run our web application using Python 2.7 on Google’s App Engine Standard. We love Python for a lot of reasons — most notably the language’s readability and concision. On the other hand, we have some engineering problems we’re having trouble solving with Python 2.7: parts of our site are very slow, and our hosting costs are skyrocketing due both to increased traffic and the new features we’re adding to make the best possible learning experience.
As part of our 2018 healthy hackathon, I decided to test what it would look like to serve some user-facing requests using a Kotlin-based application running on App Engine Flex. (Kotlin is a modern, statically typed, compiled programming language that runs on the Java virtual machine.) After seeing some very positive efficiency results, and having had a positive developer experience during the hackathon, we decided to go ahead and adopt Kotlin as a second language for server-side development at Khan Academy.
The rest of this blog post will take you through what went into the hackathon experiment, why we chose Kotlin, the results of the experiment, the challenges we faced, and what’s the future of Kotlin at Khan Academy.
Experimenting with Kotlin during the hackathon: a service for analytics events
If you’ve ever watched your browser’s devtools while you’re clicking around khanacademy.org, you might see a bunch of requests to /api/internal/.../mark_conversions. This is our API for recording analytics events from web clients. We collect data such as how many times a person has attempted to solve a particular exercise and how that person navigates around the site. We use these data, for example, to ensure that a redesign of the subjects menu hasn’t accidentally made it impossible to find things on the site, or to verify that changes to our exercises based on the latest external pedagogy research actually helped students learn better.
The API’s implementation is pretty simple: it parses out information from the JSON the client sends us, adds extra information from the HTTP headers (for instance, whether it was a phone or a desktop computer), and then sends the information to Google’s BigQuery, our analytics warehouse.
Despite being so simple, this API endpoint had recently climbed to account for more than 10% of our total server costs. We hypothesized this was due to a relatively high per-request overhead. (This API serves a very large number of very small requests.) We wondered how much we could improve our costs if we wrote a separate service optimized for serving just this one API endpoint.
Enter Kotlin, which we’d used for a previous experiment with microservices at Khan Academy. (We’ve also used it for some of our internal tools.) We’d found it to be both very fast and fairly pleasant to work with. We decided to proceed with writing a Kotlin service to serve this one API, direct traffic to the new API, and compare the number of servers we needed before and after the transition.
Interlude: why Kotlin?
To be frank, our Python code has a lot of room for optimization within Python, so why start over in a new language? Adding an additional language means there’s a lot of new developer training, mental overhead due to switching between languages, and infrastructure code that needs to be written twice.
To be clear, our goal is not to rewrite the entire Khan Academy site in Kotlin (or any other language). (Code rewrites can often be disastrous.) Instead, we want to be able to take a few critical (or costly) parts of our codebase and optimize them to the extreme. But there was a sense, especially on the infrastructure team, that we were sometimes being limited by our tools.
When picking a new language to complement Python, our most important requirement was that we could use existing Google cloud libraries, since we run almost entirely on Google’s cloud infrastructure. This limited us to the languages that Google cloud officially supports — Python, Java, C#, Go, Node.js, and a couple others — or a language that can easily use libraries for these platforms.
We landed on Kotlin because it has excellent interoperability with Java, and it’s very different from Python in several ways that let us better optimize a piece of code according to its requirements:
- Insofar as it’s possible to make general statements about a language’s performance, Kotlin is fast, while Python is… not.
- Kotlin has a static, yet expressive type system; Python is dynamically typed. We don’t necessarily think static typing is always a win: in some situations static typing with a well-designed type system can help developers write code that has fewer errors and is easier to refactor, while in other situations it can decrease developer productivity by making code that would have worked fine anyway unnecessarily hard to read. But now we can choose static or dynamic typing based on a the requirements on a given piece of code.
- Kotlin code conventionally uses a functional/immutable style, whereas Python conventionally uses a more imperative style. Each style has a place, but having both Python and Kotlin gives us a choice here too.
- Kotlin (on the JVM) supports true parallelism within a single process, whereas Python (in the CPython implementation available to us) does not, due to the global interpreter lock. This gives us more flexibility to do asynchronous background processing, or to serve more requests simultaneously.
The implementation
To test, we set up a new service running on App Engine Flex, based upon a minimal Ubuntu image with OpenJDK 8, into which we compiled a small web application based on the Spark web framework. This application reimplemented the single API endpoint we wanted to port, along with a bunch of supporting middleware for things like Khan-compatible authentication and request annotations for analytics.
The result was actually a fair bit of code, so we didn’t want to switch everyone over at once. In order to allow this gradual transition, we passed down a feature flag to our client-side code that chose on a per-person basis whether to use the old Python version of the API or the new Kotlin version. By controlling the percentage of people for whom the feature flag was set, we could gradually roll out to more people.
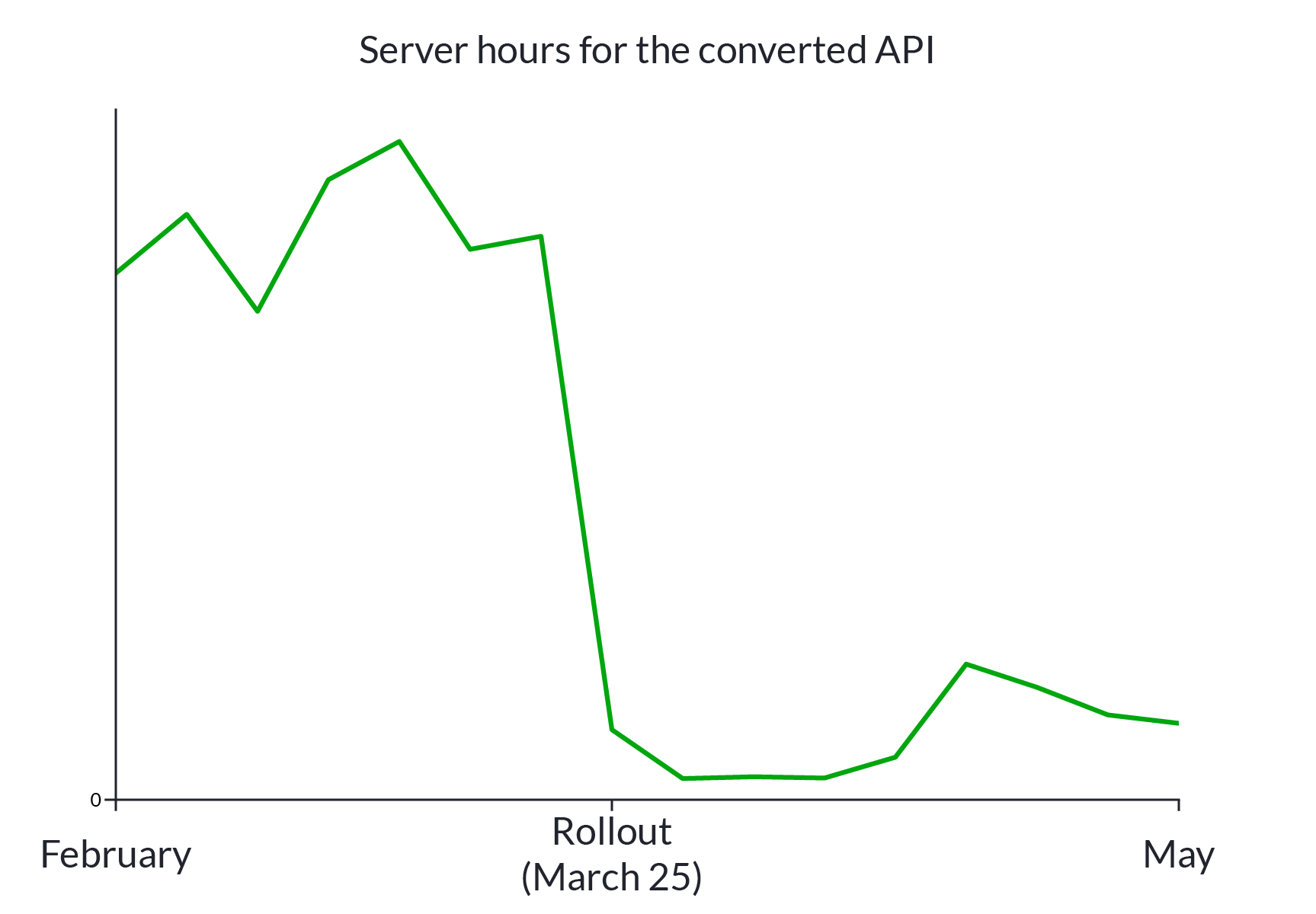
We initially rolled out to Khan Academy staff only, and when that looked ok, we rolled out to 5% of people for a few days, and then gradually upped that to everyone over the course of another day. All in all this went relatively smoothly, though there were a few hiccups that we’ll discuss further in a moment.
Results
Because our old Python API was running on a set of multithreaded instances (virtual servers) that were concurrently serving a bunch of other APIs, it was not straightforward to directly compare the cost and performance of the old version to the new one. Instead, we looked at our peak daytime instance counts before and after the rollout to estimate how many instances were required to serve all the API traffic on the two versions. After the rollout, the module serving our Python API requests peaked at requiring around 400 instances fewer than it needed before the rollout, and the Kotlin module (serving only this one API) stayed below 50 instances, meaning that one of our Kotlin instances is able to serve roughly 10x the requests that the Python version could serve.
In addition, because the particular App Engine Flex instances we’re using are about 4x cheaper than the (App Engine Standard) Python instances we used before, this represents even more than a 10x cost savings on this route for us.
Challenges
During the rollout, we did encounter some unexpected challenges. The most interesting was maintaining backwards compatibility of the data we were recording for analytics. While we knew this would be an issue and wrote unit tests for our code to make sure this was as close as possible, there were some subtle differences our tests didn’t catch that caused issues.
An example of this was small changes in user agent parsing: we couldn’t use exactly the same library for user agent parsing in Python and Kotlin, and there were small differences in how they converted user agent strings into device and browser information. Uncaught user agent parsing differences propagated into our analytics code for calculating learning sessions — if you switch devices, we start counting a new session — which in turn propagated into the code that calculates total time spent learning. Total learning time is one of a few key metrics we use to evaluate how new features we deploy are affecting learning on the site; it’s very important to keep it consistent over time, and at first our rollout didn’t do that.
How did these differences slip through the cracks? While many of them did not, and were caught either by manual cross-browser testing or by automated tests, testing didn’t find all of them. To catch issues that tests may not, we also have monitoring for step changes in our key metrics that alert people to the possibility of bugs being deployed. Even with this monitoring, it took us a while to notice the user agent differences because we happened to deploy the new Kotlin service during one of a few common weeks for spring break in the US public school system, so the overall changes in our traffic patterns masked the issues caused by the rollout.
It’s still an active area of effort to come up with better ways to monitor and test our key queries for analytics. A few years ago, we developed tinyquery, a Python library that’s an in-memory test stub for Google’s BigQuery. While tinyquery is very helpful for us, it still relies on us having generated and used test fixture data that is up-to-date and contains enough variety to detect any issues. The data engineering team at Khan is thinking about better ways to generate or sample fixture data for our key metrics, as well as additional query monitoring tools, and hopefully you’ll hear from us in a future blog post about our efforts here.
The future
Adding and maintaining another language in our codebase is no small effort. We’ve built up a lot of shared knowledge, practices, and tooling around our Python code, and we largely have to start from scratch with Kotlin. But we think it’s worth the effort because the performance and cost gains can be very significant. For our learners, a faster site translates directly to less time spent waiting and more time spent learning. For us, a less expensive site means less money spent running inefficient code and more money spent on making the best possible learning experience.1Reminder: we’re a non-profit, and you can [donate](https://www.khanacademy.org/donate) if you want to help us achieve our mission of a free, world-class education for anyone, anywhere.
What’s up next for Kotlin at Khan Academy? First and foremost, learning! We’re compiling resources and guides internally to help people onboard to Kotlin programming. We’re setting up starter projects in Kotlin to help people learn with hands-on experience in bite-sized pieces. And our analytics, content creation, and internationalization teams are trying Kotlin for some of their internal tooling, giving us experience with medium-sized projects with relatively isolated codebases. In parallel, continued efforts to untangle and refactor our existing Python codebase will yield more isolated APIs that are easier to port to Kotlin if and when the time comes to do so. All in all, with Kotlin we now have another great tool available at Khan Academy for writing the best software we possibly can, in order to provide the best possible experience for our learners.



