By Ragini Gupta
Data is very crucial to Khan Academy and is itself an internal product for the company. Analysts, engineers and marketing are some of the daily consumers of data. We have various systems for managing pipelines which are self-contained processes for doing analysis on some data. They consume some input and produce some output. There are more than two hundred data pipelines in the company currently and the number is constantly growing.
We at Khan Academy realized the importance of having an efficient way of managing our increasing number of pipelines and the result was… Khanalytics.
Life before Khanalytics
There was no single place where one could find all pipelines:
- Some were very well tied to our website and resided in our cloud infrastructure along with the rest of our application.
- Some pipelines were more manual and generated data by manual querying.
- Some were using R scripts and were run manually on local machines.
- Some were hosted on a separate machine and run using a cron service.
We had complex pipelines with different stages that couldn’t talk to each other:
- Some pipelines were complex enough to have their different stages written in different languages or use different tools.
- There was no way we could use R, Python, Google BigQuery, Google Cloud Dataflow etc. in the very same pipeline and pass data between those stages.
The pipeline iteration process was slow:
- Since most pipelines lived with the code of rest of the website, changing an existing pipeline or creating a new one required many of the same steps as building user-facing functionality.
- Scheduling a single pipeline also involved multiple steps every time.
- Debugging pipeline failures was hard as the logs were either not easy to find or not informative enough.
It’s too easy to introduce bugs:
- Since most pipelines existed with the website codebase, a bug in the pipelines’ code could introduce errors on the complete website.
Khanalytics: a platform for data pipeline lifecycle management
It’s easier to describe Khanalytics by talking of its features:
- Completely sandboxed environment for running batch jobs.
- A web user interface that’s user friendly and aimed to be used by non-developers as well.
- Ability to parallelize different steps in a pipeline automatically.
- Single place to find all logs for debugging.
- Ability to schedule pipelines individually and also with dependency on other pipelines.
Architecture
Khanalytics is built on some core fundamentals mentioned below.
Everything is a container: All steps in Khanalytics (called stages) including the core components of the application are completely isolated from each other since they run in containers. We use Kubernetes in Google Kubernetes Engine to create a cluster and manage deployment of our containers. We pre-build images for all containers (Python, BigQuery, R, etc.) and start a container with the relevant image. Since everything is in a container, it’s easy enough to customize or extend the types of pipelines we’d want to support.
Statelessness: All state is managed by etcd, which is a state store. The individual services communicate with etcd about the state of individual pipelines, to start any new pipelines or to update the current state of a running pipeline. This improves reliability of the application as there are fewer communication paths.
Static configuration: We store the configuration of a pipeline in a JSON format which is static. The configuration consists of the environment, individual stages, inputs, outputs and intermediates. We allow variable interpolation in the environment variables so that certain things like current date that are dynamic, are filled in at runtime. The static configuration allows us to lint it as soon as it’s created ensuring that the configuration is always valid. It also allows us to know about the pipeline in advance and how parallel its different stages are.
Scheduling: Khanalytics uses the Kubernetes scheduler to schedule jobs and run them at a specified time, once or repeatedly. This is done with Kubernetes’ inherent cron feature called CronJob.
Permissions: Khanalytics uses Google’s Identity Aware Proxy (IAP). Once a user accessing Khanalytics is authorized, they log into the application using a service account which in turn has pre-declared access to different external services which can be accessed from Khanalytics.
User-interface
While we can access and manage pipelines using a command-line tool, a user friendly UI allows for non-developer users to create, manage and view their pipelines.
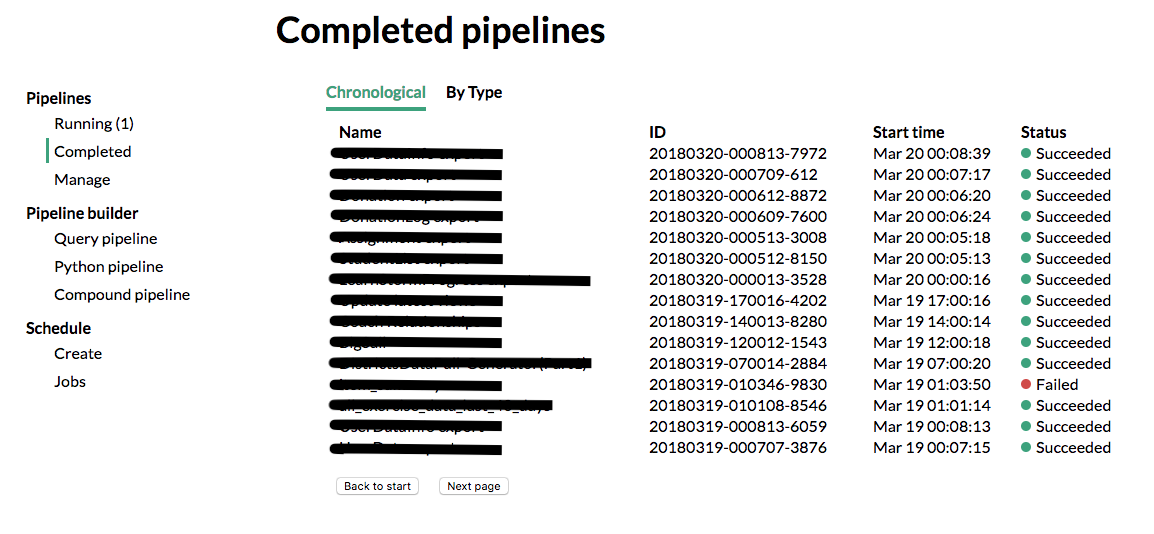
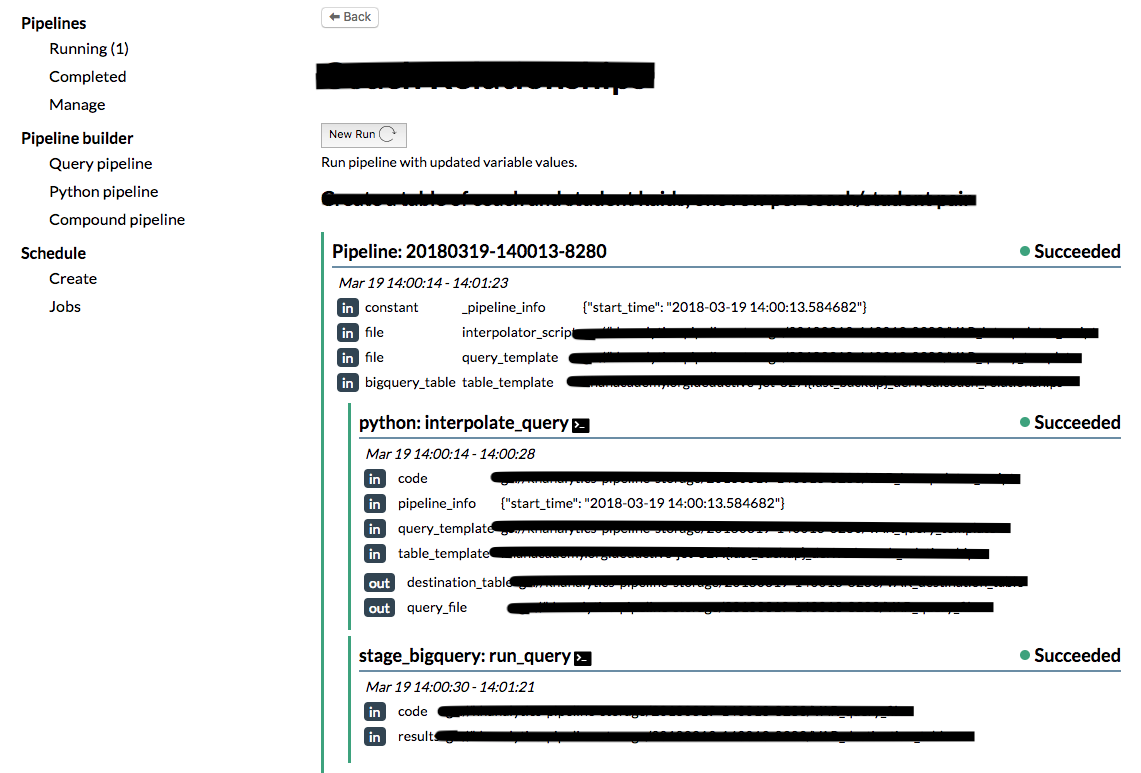
Impact
Khanalytics started as a hackathon project at Khan Academy and resulted in being our single, go-to place for managing analytics pipelines. Apart from solving the problems it was created for, we find it creating bigger impacts. It provides more empowerment to the non-developers which encourages them to create data pipelines for things that weren’t priorities for the engineering team. We saw an increase in its usage and a reduction in debugging and monitoring time. It has also promoted reusability of data or pipeline stages as a result of more visibility and easier interpretability.
What next?
We are improving the platform significantly in its reliability, usability as well as its ability to meet all needs of Khan Academy. We have a lot of work ahead of us in migrating all our analytics pipelines to Khanalytics and this migration process is also an input into testing and improving Khanalytics even more. We don’t think that we are far away from Khanalytics being the single solution to data pipelining at Khan Academy or even beyond, as we consider the possibility of open sourcing Khanalytics for others to use.
Many thanks to Colin Fuller, Kevin Dangoor and Tom Yedwab for their review of this post and a big shout-out to all who’ve worked and provided feedback on Khanalytics to help make what it is today.