
By Willow Chargin
Every month, millions of learners use Khan Academy in languages other than English. Over the past few years, we’ve built the tools to get our content translated for non-English learners, but the experience has always been far from perfect—for both our learners and our translators.
Two weeks ago, we hit a major milestone in improving this experience. Khan Academy users in Mexico may have noticed two exciting new things about our website:
users on Telcel, Mexico’s largest cell network, can now access Khan Academy free of data charges on both native apps and es.zero.khanacademy.org, thanks to partnership with the Carlos Slim Foundation and Telcel, and
all content on the Spanish-language Khan Academy site should now be available completely in Spanish, with no interspersed English!
These are both important milestones for our learners, our engineering team, and our team of translators. In this blog post, I’ll focus on the second one, discussing the infrastructure changes and optimizations that we needed to make in order to achieve this zero-English goal, and how we’ll adapt these changes to more languages.
What’s the problem?
Of course, translations aren’t new to Khan Academy. All our natural language content and all our user interface strings go through a third-party translations service called Crowdin, and we’ve even built extensive tooling to make this as easy as possible for translators. Indeed, our translations are updated many times per day, and our teams around the world translate millions of words monthly to help make Khan Academy available in other languages! Yet, until recently, we continued to have significant portions of our site appearing in English.
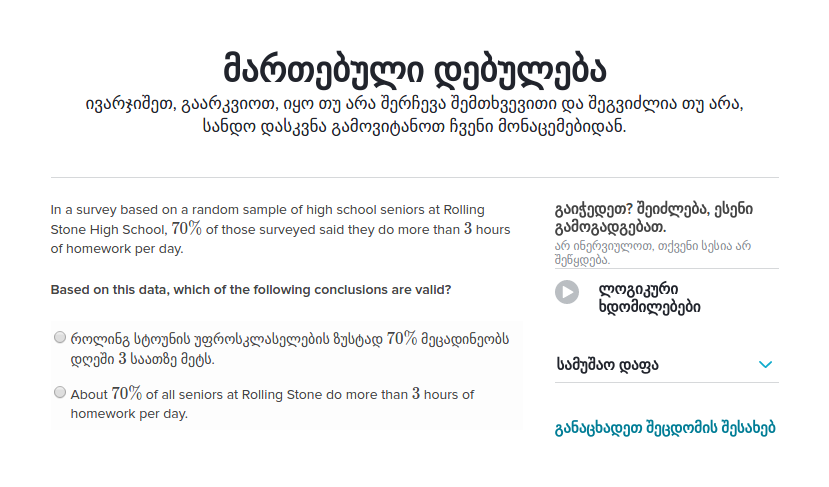
There are two primary sources of untranslated content on our site: new content and changed content.
Our content creators work in English, so all new content that they add appears untranslated initially. We’ve long had a solution to this, though: each topic has a set of “listed locales,” which we use to limit the locales in which we show the enclosed content. We can simply set new content to only be listed in English; then, we can gradually add the content to more and more locales as translators translate it. While this may not be optimal (as it requires manually updating these listed locales whenever translations are completed), it works fine and solves the problem of new content appearing untranslated.
The larger problem is changes to existing content that’s already live on international sites. If we add a section to an article, or introduce some new problem types in an exercise, then those new strings will be visible immediately—but they won’t yet have translations, so they’ll appear in English. Even small changes to existing content and metadata, like removing a space at the end of a video description, or changing a straight quote to a smart quote in an article title, will technically be new strings, so will appear untranslated.
This is a pretty big problem, because our content creators publish and update content dozens of times per day, and each publish risks reverting content to English. This wipes away translators’ work, and immediately exposes learners to a language that they may not understand.
We’ve been thinking about this for a while, but it is a hard problem. Ideally, we want to give translators the ability to fix a specific version of the site, translate it, and have that version appear live for their translated site. Any further updates from the English site wouldn’t be visible on the international site until translators decide to translate it, actually translate it, and publish their updates to their site.
The first step in implementing this is simply making it possible to display different versions of the content tree on non-English sites. To actually implement this, we needed to make some wide-reaching changes to the infrastructure behind our content system.
A bird’s-eye view of our content architecture
Our site runs on top of a custom CMS. To understand the required infrastructural changes, we need to understand a bit of how the CMS works.
Each content entity on our site—videos, articles, and exercises, and also the topics into which they’re arranged—is stored in an immutable Python object, called a Video (etc.). The cache of all these frozen models is stored in memory on each instance, so all requests have essentially instant access to all of our content. For evident reasons, we call this cache the frozen model store, or FMS, and we’ll be coming back to it a lot as it’s the core data structure for the site!
When a content creator makes a change to, say, update the description of a video, we create a new VideoRevision entity on the server; just like the corresponding frozen model, this entity contains all the metadata for the content. The server also sets the “editing head” for the relevant video to point to the new revision, but no changes are made to the frozen model store until the content creator publishes the change. At publish time, we grab the most recent revisions for all the entities that the content creator wants to publish, and all the currently live revisions for everything unchanged (the vast majority). We then go through and create the frozen models for each revision, adding some metadata as we go.
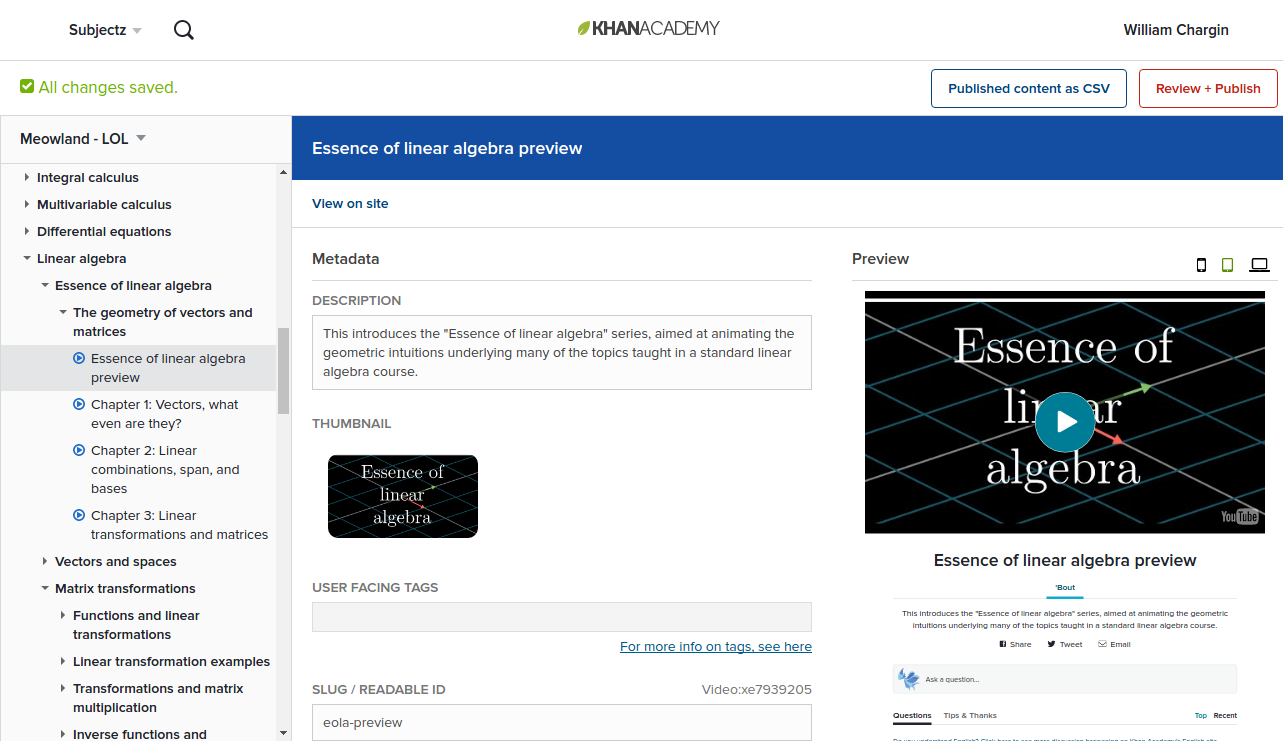
At this point, we’ve created a new frozen model store for the new version of the site. To update the live site, we simply flip a global setting called last_published_commit, which contains the SHA-1 hash of the currently live FMS. At the beginning of every request, each instance will make sure that it has the most recent SHA, and will pull in the latest version of the FMS if it’s out of date, evicting the old one from its cache. All queries to our content go through the frozen model store, and all relevant caches are keyed against the FMS SHA, so the effect is that the entire site is atomically updated in about a second.
If you’d like to read more, Tom has written about how he designed this CMS and how he implemented it. But all you really need to know for now is that the whole frozen model store is keyed by SHA and stored in a big in-memory cache.
The one-line solution
There is a conceptually simple way to achieve our goal of freezing a version of the site to appear in Spanish. All we need to do is identify the SHA of the content version that we want to freeze, and then use that SHA in place of the default SHA on the Spanish-language site, by hooking into the global setting.
It turns out that this is pretty easy to implement, too. We can simply change our last_published_commit string to a last_published_commits dictionary, mapping each locale to its specific content version (with the semantics that locales not in the dictionary use the English tree). When evicting caches, we just don’t evict the FMS for any of the currently live versions.
This actually works impressively well. Because all content accesses are keyed against the SHA, and the SHA is computed based on the locale, all content accesses are now effectively keyed by locale as well. There were only a few places that needed to be updated further, and these were the codepaths that worked directly with the frozen model store itself (like the content publish process, which sets the global SHA setting, as well as our scripts to prime caches against a new version of the site before it goes live).
The fun part, as with any infrastructure work, is in anticipating and dealing with the downstream effects of this change.
Memory
You’ve probably spotted that this potentially doubles the memory usage of our content system: we’re now storing two similarly-sized content trees in instance memory. The first question is whether we can handle that at all.
Our frozen model store is only about 34 megabytes as stored in the datastore, but this is with all entities pickled and the entire store compressed. We cache the decompressed and unpickled form in instance memory, because we demand instant access to content. We checked on our production instances, and found that this came out to 313 MB. The App Engine instances that we use only have 512 MB of RAM, so we clearly wouldn’t be able to store two of these in memory at once. It was optimization time.
As usual, there was some really low-hanging fruit. We did some memory analysis using Python’s asizeof library, and saw that articles were taking up a disproportionate amount of space. Upon closer inspection, the cause became clear—out of videos, exercises, articles, and topics (our four content kinds), articles are the only kind with any non-trivial content stored in the FMS other than metadata. For instance, all of our video content is hosted entirely on YouTube. But we were storing the body of every article as Perseus content in the frozen model store.
The frozen model store wasn’t intended to store this kind of data, but obviously we have to store it somewhere. Our solution was simple: just don’t store the content in the FMS, and instead delegate to the ArticleRevision from which the Article in the FMS was originally created. This is essentially as simple as adding an @property to the Article class:
@property
@request_cache.cache()
def perseus_content(self):
# (shadows the old `perseus_content` attribute)
revision = ArticleRevision.get_by_sha(self.sha)
return revision.perseus_content
Because our revision types are also immutable, we don’t lose any atomicity guarantees by doing this. That is, we have an overall SHA for the frozen model store, and each frozen article also has a revision SHA that’s stored in the FMS; the composition of two frozen SHAs is still a frozen SHA.
The major concern here, then, is that the data access is no longer instant. But our request_cache.cache() decorator on the getter above fixes that, by (unsurprisingly) caching the datastore value for the duration of the request. It’s rare for a request to need to fetch the full content of multiple articles—usually, you’re either displaying the metadata for a whole bunch of them in a list, or you’re actually viewing just a single article—but this does happen when we, e.g., traverse the entire content tree. In that case, we can fetch all the relevant data with a multi-get and populate the caches, to avoid degrading to a bunch of sequential, blocking RPCs. So the overall performance hit is at most one RPC per request, which is totally fine; in return, we immediately lopped off about 60 MB of memory.
As we continued to look at the distribution of data, the long tail fell off quickly, and we ate all the low-hanging fruit without achieving the memory reduction that we were hoping for. A lot of our data was just normal dictionaries containing information that we couldn’t really see a way to optimize, like lists of problem types that apply to any particular exercise (stored as IDs, so not really compressible).
But a closer look revealed that the overhead of these containers themselves—primarily Python dicts—was a significant contributor to our memory usage! We found that the standard library’s namedtuple was more memory-efficient, but namedtuple has a different interface—point.x instead of point['x']—and we didn’t want to have to update all users (tricky in a dynamically typed codebase!). Also, using a namedtuple would have prevented us from adding or removing fields in a way backward compatible with existing pickled objects; namedtuples really are just tuples with the names stored on the class object.
To solve these, we created a type called a tuplemap, with the following key properties:
- the interface is like a
dict; - memory usage is like a tuple; and
- when pickled and unpickled, the ordering and naming of fields is flexible, like a
dictand unlikecollections.namedtuple.
If this sounds appealing, we’re open-sourcing tuplemap, as well as its successor, namedmap, and also their tests, for use in your code today! Go ahead and check ’em out.
By replacing some of our heavier collections with this type, and also interning the strings used as keys when unpickling the objects, we knocked about 120 MB off of the frozen model store size. This was sufficient—we were good to go on the memory front!
The fly in the ointment
There was just one tiny catch to all of the above, and it’s the dirty little secret of the frozen model store: not everything is actually immutable.
In addition to the videos, exercises, and articles that power much of our content, we have entire computer programming and computer science curricula. We’d be remiss to teach these without offering a way for users to create their own programs, and so indeed we do offer programming playground environments, called “scratchpads,” for JavaScript, ProcessingJS, HTML, and SQL. We also use these scratchpads in our official content, both for CS tutorials and as demos and explorations on the rest of the site as well.
But these scratchpads are clearly fundamentally different from the rest of our content, in that they can be created by users. When a user creates a scratchpad, we obviously don’t add it to the frozen model store (we have about 14 million of them, for one thing!), and additionally scratchpads’ content is mutable. So when we use a scratchpad as part of our official content tree, the only thing we include in the frozen model store is the scratchpad’s database key.
Consequently, scratchpads can be changed outside of the normal publish process: just clicking the “Save” button on an official scratchpad makes the changes instantly visible to all users. This means that freezing a version of the frozen model store actually isn’t sufficient to freeze the whole content tree.
In an ideal world, we would already have frozen scratchpads to begin with, as a normal part of the content tree and separate from user-generated scratchpads. Perhaps in an ideal world, which is of course free of any “time constraints,” we might have taken this opportunity to introduce such a type. But this would be a pretty large undertaking, cutting across the content infrastructure, the actual content itself (we’d need to replace the database keys with newly reified scratchpads), the scratchpad viewing interface, and the scratchpad editing interface. We were really hoping that we could avoid undertaking that eight-week project.
Instead, we tried to redefine the problem. The underlying issue was that we were worried about English text seeping in to our frozen tree. Most of scratchpads’ content is code, which isn’t translated anyway, and voiceovers for our “talkthrough” tutorials, which are irrelevant because they’re not text-based (and they’re already translated separately). It turned out that the only natural language text in scratchpads boiled down to four fields of metadata: the title, the description, the criteria for peer-evaluating projects, and the suggested “next steps” after interacting with a scratchpad.
So, instead of making scratchpads themselves frozen, we introduced a new entity type: the PartialScratchpad, with just these four properties. Whenever we publish content, we grab the latest version of these natural-language properties from the live scratchpads, and attach them to partial scratchpads. Then, we added more @propertys to the main scratchpad model, making them delegate to the PartialScratchpad for official scratchpads, or fall back to the live data for user-generated scratchpads.
This was pretty easy to implement, is totally safe, and doesn’t have any downstream effects to other parts of the codebase. Although it’s not a perfect solution, it is a step in the right direction; if we do decide to fully freeze scratchpads later, we’ll have a place to start and a way to gradually migrate data.
Lessons
As usual, this is as much “lessons reinforced” as “lessons learned”! But that doesn’t make them any less valuable.
- Strive for immutability. Our content system was almost entirely immutable, and patching the part that wasn’t did not pose a big problem. If we had had to touch every API call that viewed, edited, or published content, or used a cached version of any one of those—which is basically the whole site—this process would have taken far longer and have had far more bugs.
- Identify underlying requirements, then look for 80–20 optimizations. Our approach to scratchpads didn’t totally fix the underlying problem, but it certainly didn’t make it any worse, and it totally satisfied our real goal of eliminating all English-language text from the Spanish site.
- Improving Python memory usage is tricky, but totally possible. With the help of some good tools, we were able to successfully identify the hotspots; with the help of some Python features like
__slots__, we were able to efficiently optimize them.
Results and future work
Khan Academy’s Spanish site now successfully uses a different content version than the English site. The servers are able to hold both versions of the content comfortably in memory. We can show and hide content on the Spanish tree independently of the English tree, so we can elect to show content only after it’s been translated.
Moving forward, we have a few major goals. Recall that our original vision was to allow translators to selectively pull in updated content from the English site—building the frontend and the backend for that system is at the top of our list. Then, we’ll figure out a way to scale this whole system to more than two content trees: clearly, we can’t just keep reducing the memory usage forever; we’ll need to fundamentally change the way that content is stored and/or accessed. We’ve got some ideas…
Finally, I want to highlight that I’ve used the word “we” an awful lot in this post, and not in the mathematical I-really-mean-“I” sense: this work is due to many of the fantastic people on our infrastructure and frontend teams, of which I’m honored to be a part. Do these problems sound interesting? Come join us!



