
Or, how to switch that foundation out from under your product while keeping it fully running
By Kevin Dangoor
Previously, I wrote about our “Goliath” project to rewrite Khan Academy’s 10-year-old monolithic Python 2 backend in modern Go. This blog post won’t go into the whys of the transition. If you’re interested in that, check out the earlier post.
One bit of feedback I saw when writing previously about rewriting our backend in Go was along the lines of “big bang rewrites are unbelievably risky”. I agree with that! Today, I’m writing about how what we’re doing is essentially the opposite of a big bang rewrite.
Federated GraphQL
The hub of our new architecture is based on GraphQL federation. REST-based services have had “API gateways” for years, and federation provides the same function when your system is based on GraphQL. The big differences between the two are:
- GraphQL provides a single, typed schema for all of the data the backend systems can provide.
- REST API gateways generally know how to direct a request to a single backend service. GraphQL gateways generate a query plan to build up a response that includes data from multiple backend services
At a high level, our system looks like this:
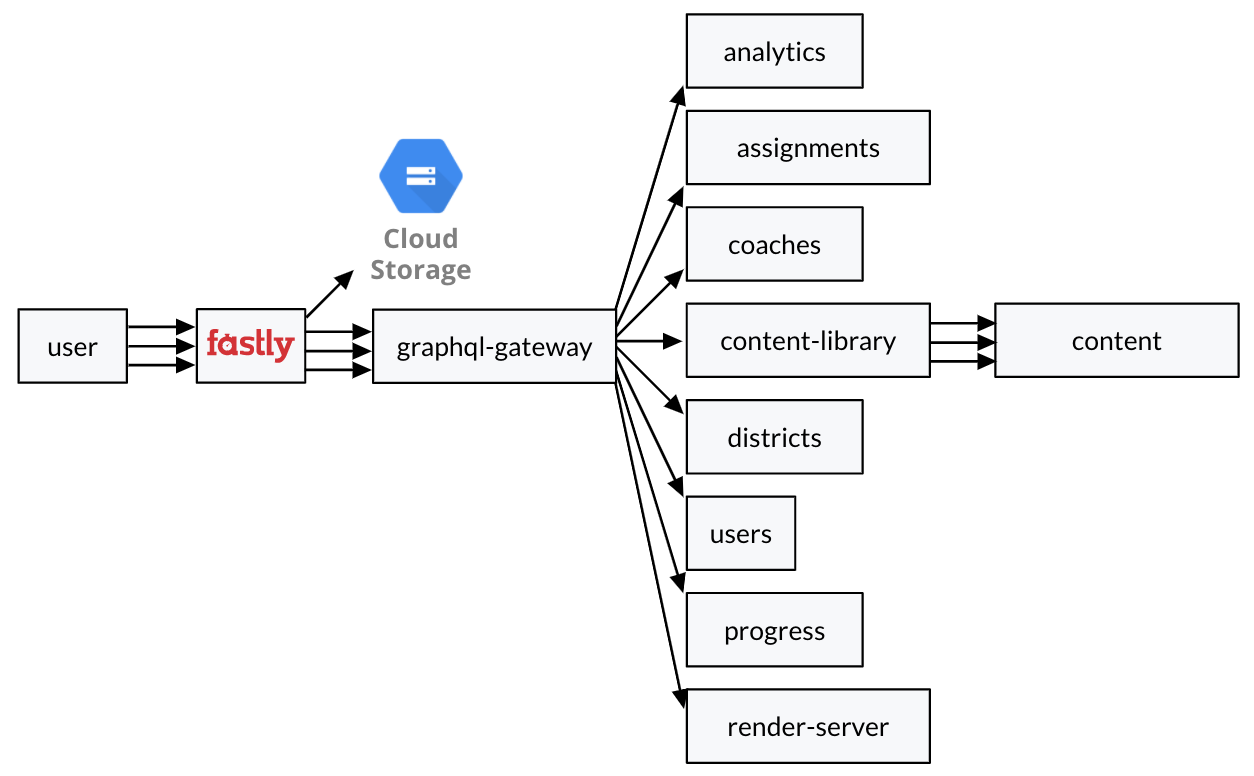
The graphql-gateway service is responsible for creating the query plan and making GraphQL requests to our other services, including our monolith. Our Go services have their own GraphQL schemas, for which we use gqlgen to respond to requests. I’m going to focus on how we’ve customized the Apollo GraphQL server to allow us to safely migrate from our Python 2 monolith to these new services.
With GraphQL Federation, each service provides part of the overall GraphQL schema and the gateway merges all of these separate schemas together into one. Our monolith acts like any other service in this setup.
Side-by-side testing
GraphQL is based on types with fields. The code that knows how to look up the value of a field is called a resolver. Here’s the simple example we’ll be using to talk about our approach:
type Assignment {
createdDate: Time
}
There are a lot more fields involved in Assignments, but our approach is the same for all of them.
Let’s say we want to move this field from the monolith to our new Go service. How can we be confident that the new service is returning the same data that the monolith did? We use an approach similar to GitHub’s Scientist library: query both the monolith and the new service and compare the results, but only return one of them.
Step 1: The monolith is in control
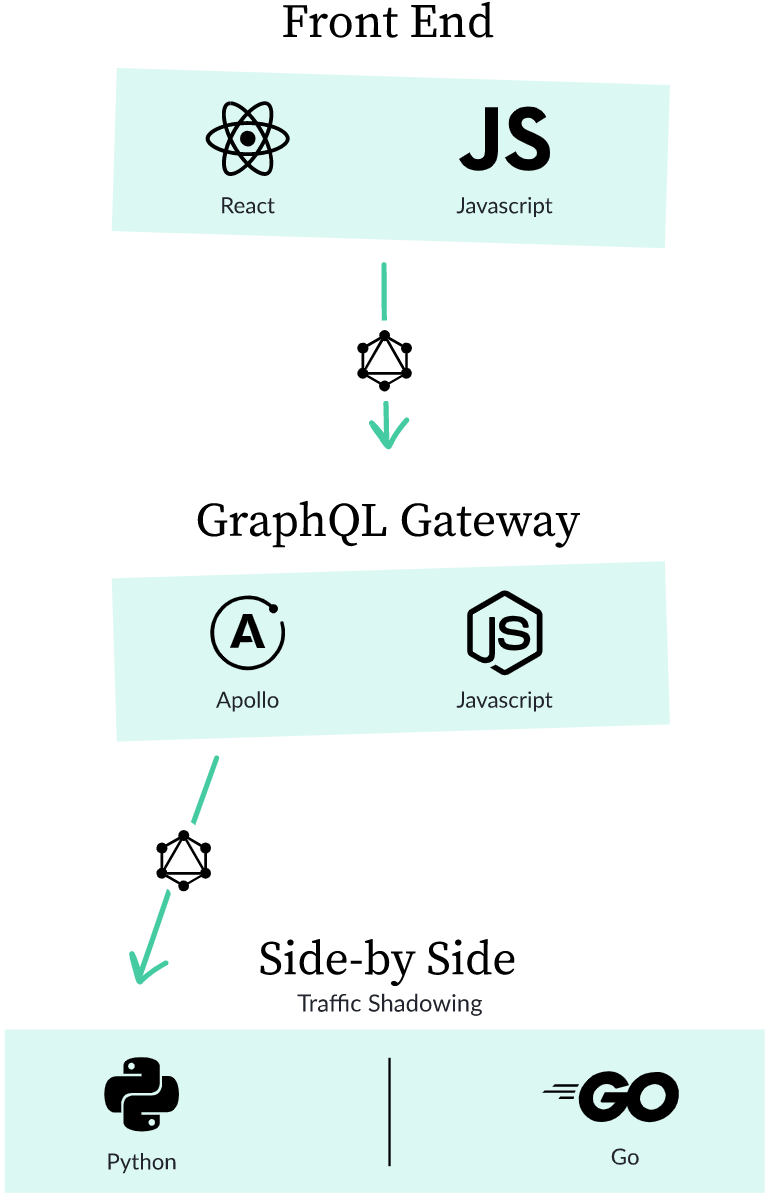
When a user requests the createdDate field, the graphql-gateway is going to make a request to the Python monolith.
Our first step is to set things up so that we can add the field in the assignments service in Go. The assignments service will have something like this in a .graphql file:
extend type Assignment @key(fields: "id") {
id: ID! @external
createdDate: Time @migrate(from: "python", state: "manual")
}
This is using federation to say that the service is adding the createdDate field to the Assignment type, and that field can be looked up using the id. The secret sauce we’ve added is the @migrate directive. We’ve written code that understands these directives to build up multiple schemas that the graphql-gateway will use when deciding how to route a query.
In the “manual” state, the query will only go to the Python code. We use this while we’re writing a new service. Our engineers can still query the service directly for createdDate or can ask the graphql-gateway for the “manual” schema, but all bets are off as to whether or not that schema is actually going to work.
Step 2: Side-by-side
Once we’ve built out the resolver code for the createdDate field, we switch the field over to side-by-side:
extend type Assignment @key(fields: "id") {
id: ID! @external
createdDate: Time @migrate(from: "python", state: "side-by-side")
}
In this state, the graphql-gateway is going to call both the Python code and the new Go code. It will compare the results, log the instances where there’s a difference, and return the Python result to the user.
This mode is really the key to building up confidence that the migration is going to work properly. We have millions of users and years of data. By seeing how this code works in the real world, we can verify that even weird edge cases are handled consistently and correctly.
Here’s a sample report that shows counts of side-by-side differences:

We do encounter cases where an non-deterministically ordered Python set yields a different result than the Go code. Over time, we’ve learned to spot these sorts of issues which don’t represent user-visible problems.
When working from our development servers, we also have tools that provide color highlighted diffs to make any variations easy to spot and understand.
What about mutations?
You may have picked up on a conundrum: If we’re running the same code in both Python and Go, what happens with code that changes data instead of just querying it? In GraphQL terms, these are called mutations.
Our side-by-side tests don’t cover mutations. We had considered some approaches to allow this, but they were more complicated than we thought worthwhile. But we did come up with an approach that helps with this problem and more…
Step 2.5: Canary
If we have a field or mutation that we think is ready, but we still want to do some production testing and validate the results, we have a “canary” mode for this.
extend type Assignment @key(fields: "id") {
id: ID! @external
createdDate: Time @migrate(from: "python", state: "canary")
}
Fields and mutations in the “canary” state will be sent to the Go service for a runtime configurable percentage of our users. Plus, internal Khan Academy users will get the canary schema. This gives us a reasonably low-risk way to test more complex changes, because we can quickly turn off the canary schema if something is not working quite right.
For efficiency’s sake, there’s only one canary schema. In practice, not many fields/mutations are in the canary state at any given time, so this shouldn’t be a problem. This is a good tradeoff, because the schema is pretty large (more than 5,000 fields) and the gateway instances need to keep the primary, manual, and canary schemas in memory.
Step 3: Migrated
The next step on createdDate’s journey is to become “migrated”:
extend type Assignment @key(fields: "id") {
id: ID! @external
createdDate: Time @migrate(from: "python", state: "migrated")
}
In this state, the gateway only sends the traffic to the Go service. The Python code is still there, ready to respond. This makes it easier to stage our deploys and roll back if something goes awry.
Step 4: Python code removed
Finally, we’re done with the Python code and can remove the @migrate directive entirely:
extend type Assignment @key(fields: "id") {
id: ID! @external
createdDate: Time
}
At this point, the Assignment.createdDate field is only known to the gateway as coming from the assignments Go service.
How has it been going?
We built our side-by-side testing infrastructure this year, and it has allowed us to migrate a bunch of code to Go safely and in tiny steps. We’ve maintained high availability during a year with a significant traffic increase and massive changes to our backend, web frontend, and mobile apps. As of this writing, ~40% of our GraphQL fields are now being served by Go services, so this technology has proven itself out for this migration.
Even after the Goliath project is done, we’ll be able to keep using this technique to shield our frontends from the inevitable changes that will come to our backend services over time.
If helping to provide a free, world-class education to anyone, anywhere through building with cool tech like I’ve described here sounds like something you’d be into, check out our careers page. We’re hiring!
Steve Coffman gave a talk on this topic at Google Open Source Live, and you can see a recording of that talk on YouTube as well (or view his talk slides). Thanks also to Dhruv Kapadia and Jeremy Gervais for doing much of the work on our side-by-side testing infrastructure and for reviewing this post.
You can comment on this post on Hacker News or Reddit.



